
A Crash Course in Kubernetes #1: Overview
Learn You a Kubernetes for Great Good
Hello and welcome to our new blog post series, “A Crash Course on Kubernetes”! Our summer intern didn’t have a background in Kubernetes, so to get her up to speed, we started giving internal Tilt University presentations on relevant concepts. This was a great crash course for our intern, but even our experienced engineers learned things at these talks–turns out, you can work within Kubernetes pretty effectively and still have large gaps in your mental models.
We’re blogifying our Tilt U presentations so that other folks can benefit from the digging we did. This is post #1 of the series, where we discuss what Kubernetes is at the highest level, and explain why you should care. The subsequent posts will dig a little deeper into the building blocks you’re likely to tinker with when you’re starting out: post #2 (now live!) covers nodes (including the machinery of the master node), and post #3 will cover pods + services.
Without further ado:
What Is Kubernetes?
“Kubernetes is an open-source container-orchestration system for automating application deployment, scaling, and management.”
Let’s break that down.
“Kubernetes”
Greek for “helmsman” or “captain” (hence the ship’s-wheel logo). Often abbreviated as “k8s” (for the 8 letters between the ‘k’ and ‘s’).
“open-source”
It’s right there on GitHub!
“container-orchestration system”
Here’s where it gets interesting. I’ll assume you know what containers are1. But what is an “orchestration system”?
Orchestration is the automated configuration, coordination, and management of computer systems and software–that is, it handles things like scaling (how many servers are running my app, and what kinds of machines are they? What happens when one goes down?), connectivity and security (how do my apps talk to each other?), and databases and other extra components of your system.
All of these things could be set up by hand by a beleaguered ops person, of course, but the great thing about orchestration is that it’s automated: in this case, you tell Kubernetes things like “I want 4 of app A and 8+ of app B running at all times, app B scale in response to traffic like X, and they talk to each other like Y,” and Kubernetes makes it so.
Kubernetes Architecture
Generally speaking, Kubernetes is containers all the way down. You bundle your app in a container, and it’s run on a pod (which is also a container, but you don’t need to worry about that.)
A pod is the basic unit of your app; the unit that you scale, the unit that your networking talks to, etc.
Pods talk to each other and to the outside world via services; a service defines a set of pods and rules for communicating with them, from inside or outside the cluster.
Pods run on nodes; nodes are machines (physical or virtual) managed by Kubernetes which run 1+ pods, and some other daemons that let Kubernetes communicate with them. Everything on your cluster is managed by the master node, which is like any other node except that, instead of running pods, it instead runs all the machinery that lets Kubernetes store/detect/change state, lets kubectl talk to the cluster, etc.
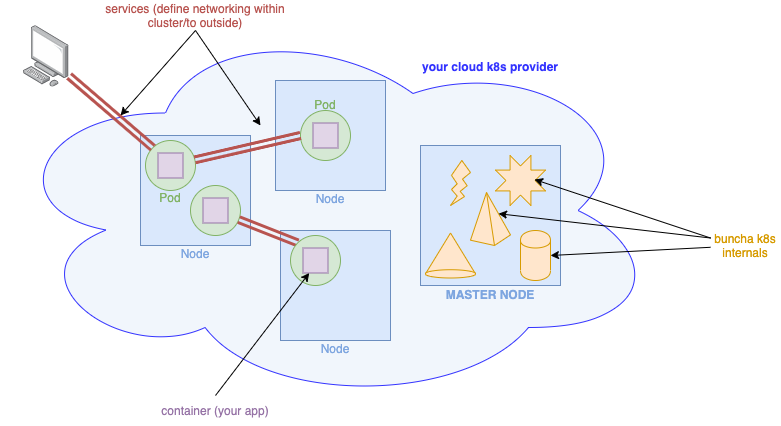 An extremely high-level, hand-wave-y architecture diagram.
An extremely high-level, hand-wave-y architecture diagram.
Where does all this live?
The short answer is: in virtual machines! Kubernetes nodes are generally all VMs, which may be located on your computer–when using local Kubernetes runtimes like Minikube, Kubernetes for Docker for Mac, or Kubernetes in Docker (KinD)–or in the cloud–when using runtimes like Google Kubernetes Engine (GKE) or Amazon Elastic Kubernetes Service (Amazon EKS).
The even shorter answer is: it doesn’t matter! You as the user don’t need to know the location of the VM(s) that you’re talking to; all you need is the address of the Kubernetes API server, which lives on the master node and allows you (via kubectl) to communicate with the rest of your cluster. If your kubecontext knows where the API server lives, then it doesn’t matter whether it’s on a VM in your own computer or on a server in some far-flung AWS AZ – just send it a command, and Kubernetes will take care of the rest.
Okay, why should I care?
Well, you don’t have to! Everyone uses Kubernetes at a different level of abstraction; for instance, I operated quite happily for a while without understanding precisely how a kubectl apply command results in a new pod… until I needed to know, and then this knowledge gap came back to bite me. That won’t even necessarily be the case for you–maybe you’ll never need this knowledge of the guts of Kubernetes–but it will probably help your debugging abilities if you have accurate mental models.
We hope this series helps new and experienced Kubernetes users alike get a better handle on what’s going on under the hood–even if we’re only scratching the surface of the complexity of Kubernetes. See you next time!
Further reading
Check out the next post in this series, where we talk all about nodes—the machines that run units of your app, and the means by which Kubernetes controls your cluster.
The official Kubernetes Tutorial and Kubernetes Concepts documentation is a great place to start learning more. For a digestible and fun high-level overview, I recommend this Kubernetes comic. And if you want to start playing around with Kubernetes on your laptop, Tilt is a great way to quickly iterate on your configs; just change a line of YAML and see what happens!
-
Briefly: “A container is a standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another. A Docker container image is a lightweight, standalone, executable package of software that includes everything needed to run an application: code, runtime, system tools, system libraries and settings.” (From Docker: What is a Container?) ↩
Related

A Crash Course in Kubernetes #2: Nodes


Live Update Multiple Containers Per Pod